New AI Model Architecture MoR
By Stuart Kerr, Technology Correspondent
Published: 3 August 2025 | Last updated: 9 May 2026
Contact: [email protected] | Follow @LiveAIWire on X
Author Bio: https://liveaiwire.com/p/to-liveaiwire-where-artificial.html
The Architecture That Powers Every AI You Use Is Being Challenged
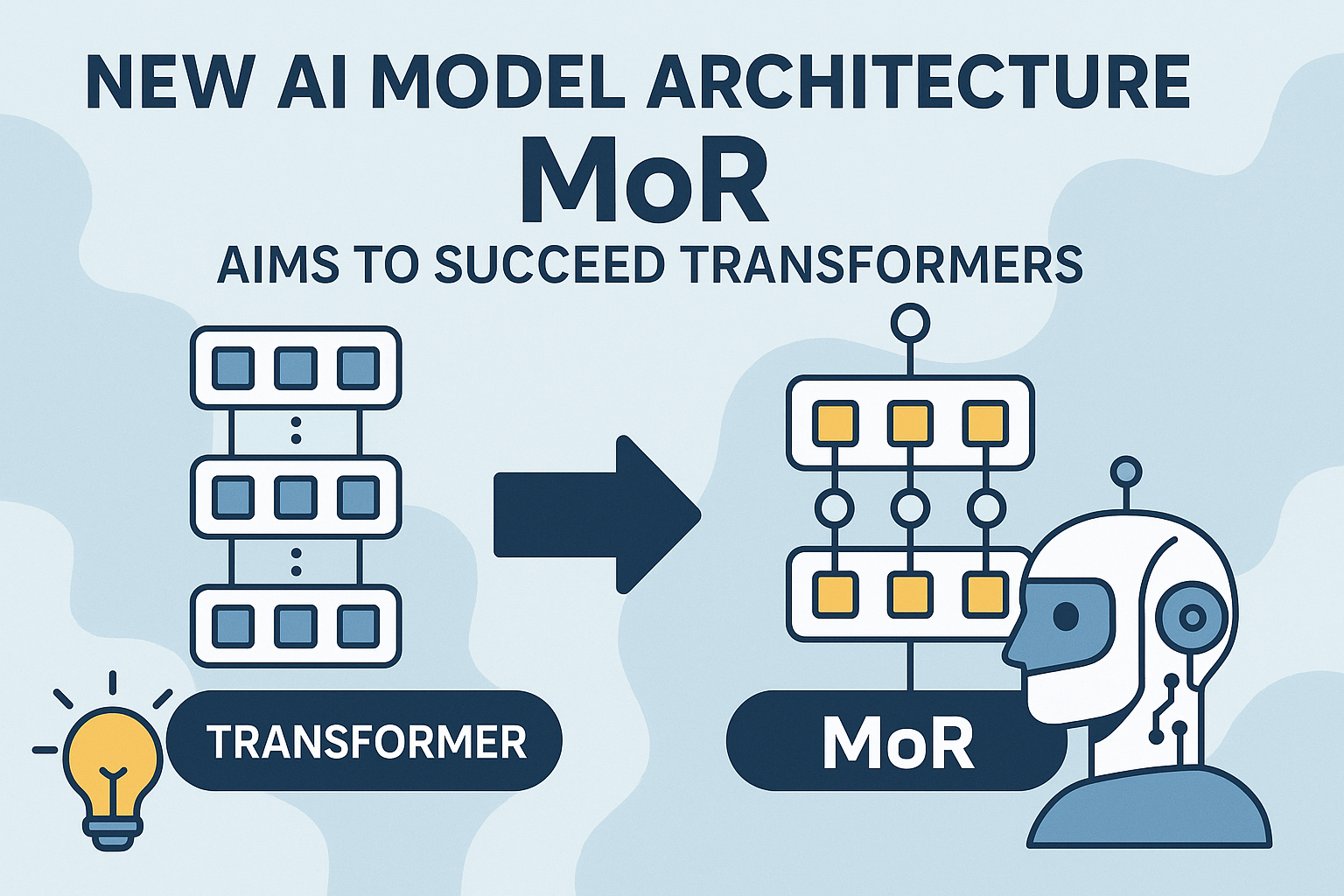
The AI model architecture race is now one of the defining technology stories of 2026, and MoR sits right at the centre of it. In 2017, Google’s paper “Attention Is All You Need” introduced the Transformer architecture, the backbone of every major AI system today, from ChatGPT to Claude to Gemini. It was one of the most consequential research papers in the history of computing. Now, in 2025, Google DeepMind has introduced something that may eventually succeed it: the Mixture of Recursions, or MoR, a new architecture that is smaller, faster, and in many benchmarks, more capable than the Transformer models it aims to replace.
Understanding why this matters does not require a computer science degree. The Transformer processes every word or token in a sentence by sending it through every single layer of the model, regardless of whether that word is simple or complex. MoR thinks about this differently. It introduces a small router that scores each token and decides how deeply it needs to be processed. Simple words exit early. Complex reasoning gets more compute. The result is a model that allocates effort where it is actually needed, much like how a human reader skims familiar ground and slows down for difficult passages.
What MoR Actually Delivers
According to VentureBeat, MoR delivers up to two times faster inference by restructuring how token dependencies are handled. Internal DeepMind benchmarks show MoR outperforming Transformers on most natural language processing tasks while cutting latency by 40 percent. Crucially, it also halves the key-value cache memory that models require during inference, which translates directly into lower running costs and more efficient deployment on smaller hardware.
The MoR-ViT technical paper extends these findings to vision models, showing that the same recursive approach achieves equivalent accuracy with fewer parameters and substantially faster inference. That makes it attractive not just for large cloud deployments but for real-time systems and edge devices where compute is constrained.
As explored in Invisible Infrastructure, foundational architecture choices shape every layer of the AI systems people interact with daily. MoR is exactly that kind of inflection point.
The Broader Post-Transformer Race in 2026
MoR does not exist in isolation. By 2026, the AI research community has moved firmly into what analysts are calling the consolidation phase, where the goal is no longer simply proving that large models can reason and act, but making them efficient, adaptable, and capable of operating in real-world environments without prohibitive computational costs.
Several competing approaches are gaining serious attention alongside MoR. State Space Models, including the Mamba architecture developed at Carnegie Mellon, offer linear scaling that avoids Transformers’ quadratic complexity, making them particularly effective for very long context windows. Researchers at the University of Pennsylvania have developed Mollifier Layers, a technique integrating classical mathematical smoothing functions into neural networks to solve complex equations with greater stability. Gartner projects that 40 percent of enterprise applications will embed AI agents by mid-2026, which is creating urgent demand for architectures that can operate efficiently at scale without the energy and hardware costs that current Transformer-based systems require.
The economics of AI infrastructure are driving this architectural shift as much as academic curiosity. With AI compute demand growing rapidly, MoR’s cost savings on power and hardware are not just a technical upgrade. They represent a meaningful sustainability argument and a real competitive advantage for any company that adopts next-generation architectures early.
The End of Transformers? Not Yet
It would be premature to declare Transformers obsolete. They have a decade of research, optimisation, and engineering refinement behind them and remain exceptionally capable across a vast range of tasks. The most likely near-term outcome is not a clean replacement but a hybrid future, where models incorporate recursive and recurrent mechanisms alongside traditional attention for tasks requiring global, long-range reasoning.
What MoR represents is the clearest signal yet that the AI community is serious about moving past the limitations of pure scaling. The Transformer was a revolution in what AI could do. The post-transformer era will be a revolution in how efficiently and accessibly it can do it, which ultimately matters just as much for the billions of people who will rely on these systems. From AI and real-time language translation to the energy footprint examined in Algorithmic Hunger, the architecture running beneath every AI application is about to change in ways most users will never see but everyone will benefit from.
About the Author
Stuart Kerr is the Technology Correspondent for LiveAIWire. He writes about artificial intelligence, ethics, and how technology is reshaping everyday life. Contact: [email protected] | Follow @LiveAIWire on X.